
The ongoing discussion between OpenAI and DeepSeek has introduced a fascinating concept that will likely shape future conversations around AI development: distillation. OpenAI is accusing DeepSeek of distillation, a process where a smaller, more efficient language model is trained using responses from a larger, more advanced model.
What Is Distillation?
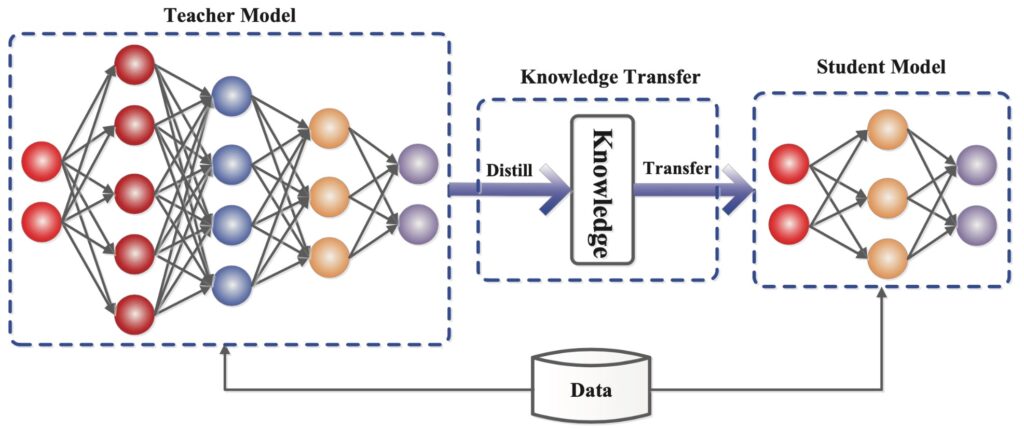
Distillation is a machine learning technique where knowledge from a large, complex model (teacher model) is transferred to a smaller, lightweight model (student model). This is done by training the student model on the output of the teacher model, rather than raw training data alone. The goal is to retain as much knowledge and capability as possible while reducing computational costs, memory usage, and latency.
Key steps in distillation include:
- Generating Soft Labels: The larger model predicts probabilities for different possible outputs, providing richer supervision than traditional hard labels.
- Training the Smaller Model: The student model is trained on these soft labels, learning patterns in a way that approximates the teacher’s reasoning.
- Knowledge Transfer: The student model gradually approximates the teacher’s performance while being significantly more efficient and lightweight.
This approach is particularly valuable in AI optimization because it allows for a balance between performance and efficiency, reducing redundancy while leveraging existing advancements.
The Unique Optimization Path
What makes this optimization approach interesting is its dual-model strategy. Instead of aiming for a single high-powered AI (like ChatGPT), DeepSeek is effectively creating two models:
- A fully-equipped, high-performance model akin to OpenAI’s GPT.
- A lightweight, cost-efficient model that delivers similar results with far fewer resources.
This means that AI development isn’t just about making the most powerful model—it’s also about reducing complexity while maintaining performance.
Projecting This Method in Research & Development
How can we apply this principle in our own work, particularly in research and development? The idea of leveraging advanced insights to refine and streamline future iterations can be instrumental in optimizing innovation cycles. Here are some key ways this approach can shape R&D efforts:
- Experimentation & Prototyping: Instead of treating every prototype as a standalone iteration, we can introduce high-resource experimental models designed to extract detailed insights. These models could be more advanced, using additional computational power and sensors to collect in-depth data.
- Knowledge Transfer & Iteration: Once enough data is gathered from high-powered prototypes, we can distill that knowledge into lighter, more efficient versions of our systems, reducing costs without compromising on quality.
- AI & Automation in R&D: Applying a distillation-inspired workflow to machine learning and automation in research could accelerate discoveries by using AI-driven models to conduct extensive simulations before deploying optimized versions in real-world applications.
- Cross-Disciplinary Optimization: Whether in software, hardware, or engineering design, having an initial phase of data-heavy, resource-intensive research followed by an optimization phase can create more efficient and scalable solutions.
By integrating this methodology, research teams can maximize efficiency while minimizing redundancy, creating innovative yet cost-effective products.
The Practical Impact of Distillation in Product Development
The applications of distillation go beyond AI and extend into real-world product development and industrial innovation. Some practical implementations include:
- Consumer Electronics: Companies can develop high-end flagship devices packed with cutting-edge technology, then use insights from user interactions to create more affordable versions without sacrificing key functionality.
- Autonomous Vehicles: Advanced sensor-heavy test vehicles can gather comprehensive data, which can then be used to optimize and streamline hardware in commercial vehicle models.
- Manufacturing & Supply Chain: Factories using advanced automation systems can analyze production workflows, enabling leaner, more cost-effective processes in smaller-scale operations.
- Retail & Market Analytics: High-data collection units can be deployed initially to gather detailed consumer insights, later leading to simpler, lower-cost tracking methods that still provide actionable data.
By adapting distillation strategies across industries, organizations can achieve a balance between innovation and efficiency, ensuring that cutting-edge developments are not just theoretical but also practical and scalable.
Final Thoughts
While OpenAI’s concerns over distillation focus on competitive advantage and intellectual property, the underlying principle—using learned knowledge to optimize and streamline—presents a compelling approach to product development. As we continue to work on our own systems, we should explore ways to implement this dual-model strategy, leveraging high-performance insights to refine and optimize future iterations.
Key Takeaway:
Instead of always designing for maximum power, consider a two-tiered approach: develop a high-powered learning system first, then use its insights to create a cost-effective, efficient model that delivers comparable results.
References:
- OpenAI’s claims against DeepSeek: Financial Times
- Understanding Knowledge Distillation: arXiv: Distilling the Knowledge in a Neural Network
- Applications of Model Compression in AI: arXiv: Quantifying the Knowledge in a DNN to Explain Knowledge Distillation for Classification
- AI Optimization Strategies: Neptune.ai: Knowledge Distillation